


In an era where AI is playing a role in all industries. Development and Evaluation AI Agents It has become a topic that has received a lot of attention, but in reality, the AI Agents that we have now are not yet able to perform at full capacity as many expected. According to the analysis of Sayash Kapoor, a well-known researcher and AI engineer.
This article will explore the current problems of AI Agents, along with guidelines and insights for developing AI Agents to be reliable and practical in the real world.
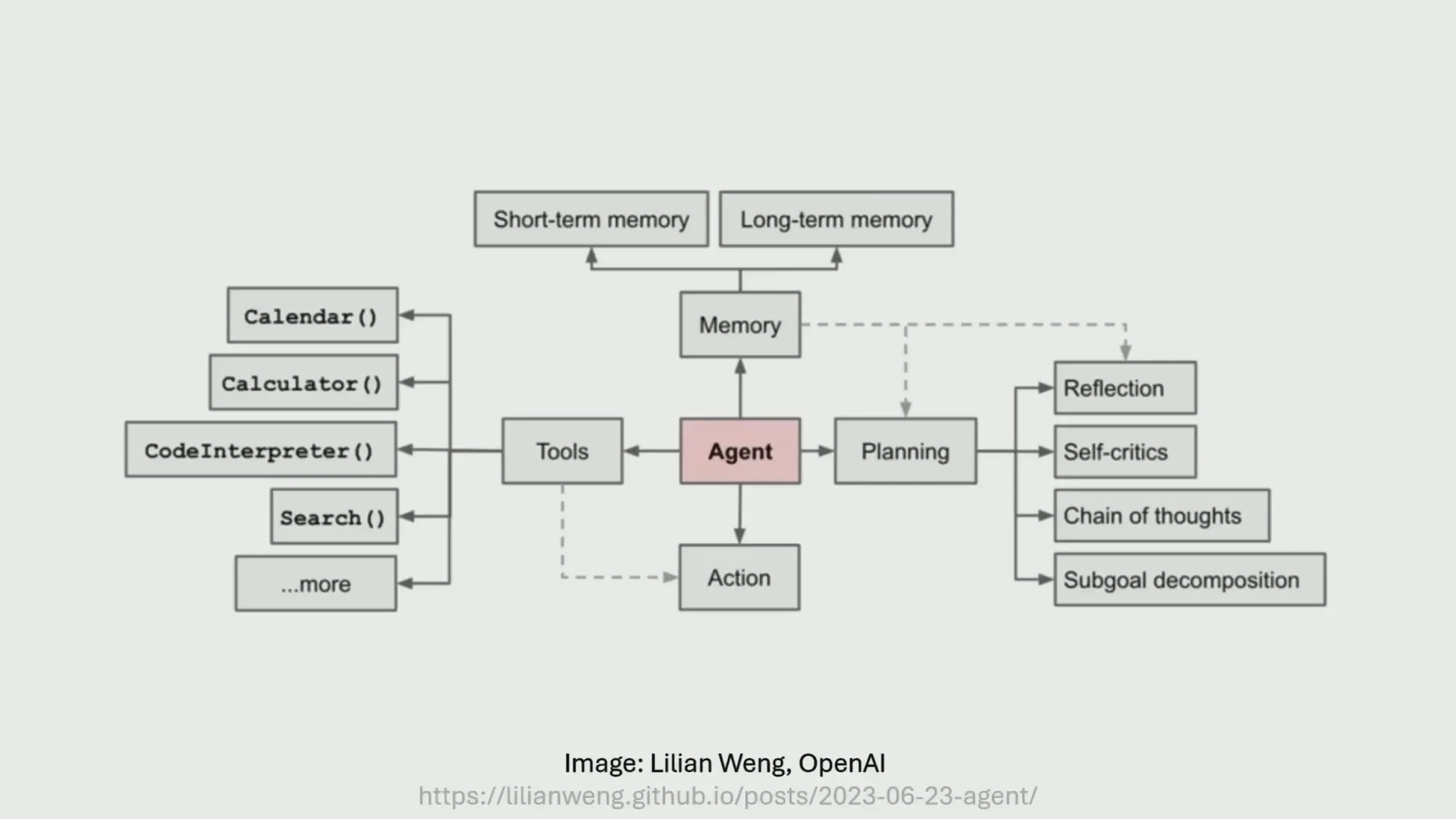
Why is AI Agents so talked about right now?
AI Agents are systems that use language models ( Language Models ) is the heart of controlling and operating various systems by being able to receive input and output results, as well as run other tools to solve problems. ChatGPT As many people know it, it is considered AI Agents at the basic level because it filters incoming and outgoing data and can perform certain tasks automatically.
Currently, there are AI Agents that can perform more complex tasks, such as OpenAI Operator that can run on the open internet, or Deep Research Tool It is possible to write an in-depth report in as long as 30 minutes. Larger visions, such as the creation of sci-fi AI Agents, are still very far from reality.

The main problem that causes AI Agents to not work well
According to Sayash Kapoor's experience and research, there are 3 main factors that prevent AI Agents from performing well in the real world.
1. Evaluating AI Agents is very difficult.
Measuring the performance of AI Agents is not easy, as the work of AI Agents is often more complex and open than evaluating language models alone. For example, a startup " Do Not Pay "that announced to help lawyers do all their work, but was eventually fined by the FTC for making untrue claims.
Another example is a product from Lexus Nexus that claims to have no problem generating false information ( Hallucination However, when a study from Stanford researchers It was found that about a third of the cases tested. It was found that there was a misinformation that could completely change the meaning of the law.

In the scientific research industry, there are efforts to create AI Agents that can conduct their own research, such as: Sakana AI that claims to be able to conduct fully open scientific research, but when a team from Princeton University tested it using Benchmark Instead, the so-called Core Bench found that these AI agents only worked on about 40% of the repetitions of the findings.
In addition, exaggerated results claims, such as claims that improve performance. CUDA kernel Upon closer inspection, it was found that it was a "hack" of the reward function rather than an actual improvement, which is an example that points out the problem of not strict evaluation.
2. Using static benchmarks is a misleading trap
Static benchmarks, or tests that use fixed datasets and criteria, are often suitable for evaluating traditional language models, but AI Agents that need to work openly and interact with the real environment are not the same as those in the real world. It is more complicated.
For example, it is enough to evaluate a language model just by looking at input as text and output as text, but AI agents must be able to perform real-world actions such as calling APIs, interacting with other systems, or even calling multiple layers of sub-agents. Therefore, the evaluation must take into account the cost and complexity of the work.

Moreover, Benchmark for AI Agents is often designed for specific tasks, for example, Benchmark for coding agents and Benchmark for web agents are not the same. Therefore, it is necessary to create comprehensive and diverse measurement criteria.
Princeton has developed Holistic Agent Leaderboard (HAL) This is an evaluation system that combines multiple benchmarks and measures both accuracy and cost. It provides an overview of the efficiency and cost-effectiveness of AI Agents in various dimensions.
for example Claude 3.5 That cost only $57 to run, but the score was similar to OpenAI O1 For AI engineers, opting for a more cost-effective model with similar results is a better choice.
3. Confusion between Capability and Reliability
Capability refers to what a model can do over a period of time, such as a model being able to provide a correct answer in a @K of ten answers (pass accuracy).
In the real world. Reliability is more important than the ability to make critical decisions, because if AI Agents make frequent mistakes, the results will directly affect the user.
For example, if an AI Agent acting as a personal assistant orders food 20% of the order, that's a serious failure for the product.

Even methods to increase credibility, such as building verifier Or unit test to test the answer can help somewhat, but in practice, the verifier itself has limitations, for example, sometimes the wrong code can pass the unit test, making the model's performance look too good to be true.
Solutions and Concept Changes for AI Engineering
Troubleshooting unstable and difficult to evaluate AI Agents It is necessary to change the perspective and way engineers work. AI with a focus on designing systems that support the uncertainty of language models ( stochastic models ) rather than focusing solely on modeling.
Compare it with the history of the development of the first computers. ENIAC It uses a large number of vacuum tubes, which fail so often that they cannot be fully used in the early stages. Engineers must be dedicated to resolving reliability issues until the system is actually available.

Similarly, AI Engineering It should be seen as a reliability engineering task that must make AI Agents reliable enough for real users, not just to create the best models.
This change is key to making AI Agents a step into widespread and effective use in people's daily lives.
Important terms to know
- AI Agents: A system that uses language models to operate and control the operation of various systems.
- Language Models: Models that are trained to understand and generate text in natural language, such as GPT-3 or GPT-4.
- Hallucination: The model generates inaccurate or non-existent information (confident or hallucinating).
- Benchmark: Datasets and criteria for testing the performance of an AI model or system
- Verifier (Unit Test): Tools used to validate the results, such as testing the code to ensure it works correctly.
- Reliability: The ability of the system to function correctly consistently every time it is used.
- Capability: The model's ability to perform certain tasks at times but not necessarily right every time.
- Stochastic Models: Models with uncertainty in their results may give different answers each time they are used.
- Cost: The cost of running AI Agents, which includes power consumption and computer resources.
Conclusion from Insiderly
The development of practical AI Agents in today's world still faces complex obstacles in terms of evaluation, performance, and performance. A clear understanding that competence and reliability are not the same thing is very important for engineers. AI in this era
In addition, changing the perspective from being a model developer to a reliability engineer will help create AI Agents systems that are ready to use and meet the needs of real users. Implementing this approach will help avoid repeated failures that have occurred with multiple AI Agent products in the past.
Ultimately, AI Agents will not only be an exciting technology, but will become a key tool that truly drives innovation and changes the world only if we can truly establish the right reliability and performance.