

In an era where AI technology is advancing rapidly. Large Language Models (LLMs) have become an important tool for processing and constructing human language. However, LLMs suffer from the problem of not being able to learn new data that occurs after the model's cutoff date.
have One of the studies The solution is "Supervised Fine-Tuning" (SFT) to enable LLMs to learn and understand new information effectively.
Methods of study
Researchers experiment with data from sporting events happening in 2023, such as the Women's World Cup and the Super Bowl, to create datasets for training LLMs. There are two ways to create a dataset:
- Token-based: Create a question-and-answer pair based on the number of words in a document.
- Fact-based (Fact-based): Focus on creating a question-and-answer pair that covers all the facts in the document. Ideal for data that requires accuracy and accuracy.
The researchers used the GPT-4 model, which has limited knowledge until September 2021, to train with the generated datasets, using LoRA (Low-Rank Adaptation) techniques to speed up the training process and make it less resource-consuming.
```
W = W0 + BA
```
Where 'W0' is the original Weight Matrix, 'B' and 'A' are Low-Rank Matrices, and 'W' is the improved Weight Matrix.
Results
- SFT actually improves LLMs: Experiments have shown that SFT can significantly increase the ability of LLMs to answer questions about new data.
- How to create an effective dataset: Fact-based datasets provide better results than tokenized datasets because they cover the data thoroughly and reduce the risk of the model getting lost in irrelevant data.
- Comparison to RAG: While SFT cannot overcome retrieval of data from external databases (Retrieval-Augmented Generation or RAG), SFT has the ability to remember data without relying on search. This makes it faster to answer questions and uses fewer resources.
- Parameter customization: Parameter customization, such as learning rate and number of training cycles (epochs), can significantly affect the performance of the model.
Limitations of the study
This study has limitations that should be considered:
- Dataset size and type: The dataset used for training may not be complete. Using a larger and more diverse dataset may yield different results.
- Model selection: Using GPT-4 as a base model may affect the results. Experimentation with other models such as Llama 2 or Bard may yield different insights.
- Generalization Ability: Models trained with SFT may have limited generalization capabilities, making them unsuitable for other types of data.
- Bias: The dataset used in training may be biased, resulting in the model producing unbiased results.
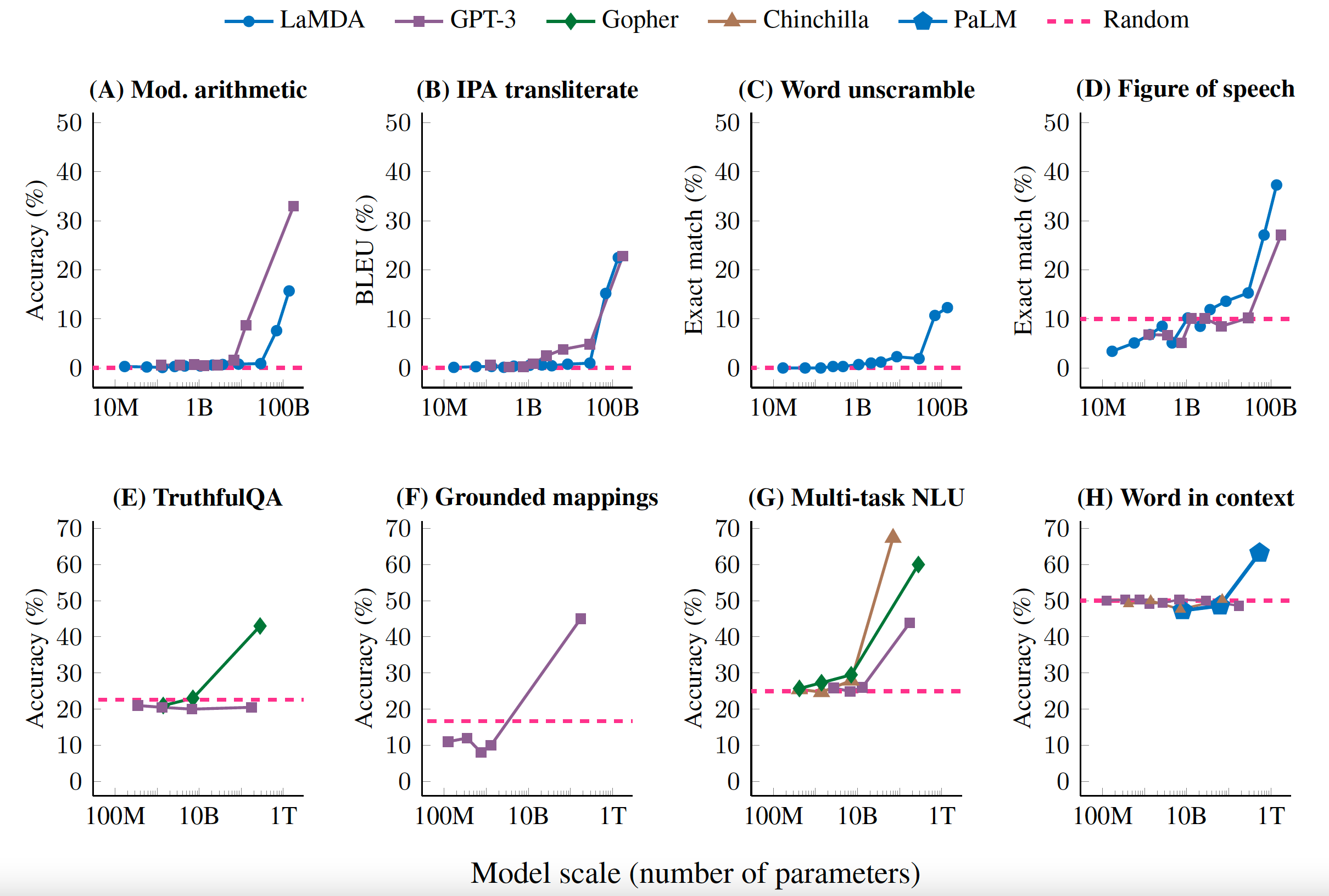
An example of the performance of LLMs vs. model size. It demonstrates the importance of model scaling to improve performance.
Importance and application
This research is important for the development of real-world AI and LLMs, especially in areas that require up-to-date information, such as:
- News and current events: LLMs enhanced with SFT can provide better up-to-date information on recent events, such as news briefings, event analysis, and more.
- Market analysis and business trends: Models can quickly learn and analyze new data in the market, such as price trend predictions. Customer sentiment analysis
- Scientific Research: LLMs They can continuously update their knowledge about new scientific discoveries, such as summarizing research and finding relationships between data.
- Education and learning: AI systems used in education can keep content up to date, such as creating exercises, providing instructions, etc.
LLMs enhanced with SFT can be applied in products such as ChatGPT, Bard, or Llama 2 to provide more up-to-date and accurate question-answering capabilities.
Ethical Issues
The development and implementation of continuously improving LLMs must take into account important ethical issues, including:
- Data management that may not be accurate or true
- the risk of using it to create deepfake content or piracy;
- Checking for potential bias in the results
summarize
This development is an important step towards making AI more resilient and adaptable.
Better cope with a fast-changing world.
However, there are still challenges in developing more effective training methods and finding a balance between learning new information and retaining old knowledge.
In the future, we may see the development of LLMs that can continue to learn and adapt, which will be beneficial in building smart and up-to-date AI systems.
Chat with research papers here